
Why Should You Consolidate Your AI Tools for Faster Scaling?...
Read MoreSupervised and Unsupervised Learning: A Comparison Guide
Table of Contents
ToggleArtificial intelligence (AI) and machine learning have emerged as the key elements in this new field of technology. Two basic approaches feed into this field: supervised learning and unsupervised learning. The primary distinction is that one makes use of labeled data to help in result prediction, whilst the other does not. There are some differences between the two strategies, though, as well as important places where one performs better than the other.

In this article, we will explore the difference between supervised and unsupervised learning.
What Is Machine Learning?
In the field of artificial intelligence known as “machine learning,” computers may learn from data to make judgments or predictions without explicit programming. The system employs data patterns rather than rigid rules to gradually enhance its performance. It has the capacity to evaluate vast volumes of data, identify obscure patterns, and offer insights that people would overlook. Algorithms and models are used in machine learning to identify these trends and adjust as additional data is processed.
What's the Role of Supervised and Unsupervised in AI Field
Two crucial techniques in artificial intelligence that help in machine learning and decision-making are supervised and unsupervised learning. The system is trained using labeled data in supervised learning, meaning that the input already contains the right output. This aids in the machine’s learning of correlations and patterns, which makes it perfect for jobs like recognizing objects in photos, detecting spam in emails, and forecasting home values. In order to comprehend how to create precise predictions when new data is introduced, it depends on explicit examples.
On the other hand, unsupervised learning uses unlabelled data, so the machine must independently identify patterns or groups. This makes it effective for finding hidden patterns or structures, such as customer segmentation or anomaly detection, that people would miss. It’s frequently employed for jobs like picture compression, market research, and network security anomaly detection. In order for AI systems to effectively and intelligently tackle a broad range of issues, both supervised and unsupervised learning are essential.
What Is Supervised Learning?
In supervised learning, labeled data is used to train a model in machine learning. Like a series of questions with their corresponding answers, this indicates that the proper output is already known for every piece of input data. The model learns to make predictions or judgments using this data.
This method is frequently employed in several daily applications. Email spam filters, which classify emails as either “spam” or “not spam,” and recommendation systems that make product recommendations based on your previous selections are powered by it. When the input and the output have a clear link and there is sufficient labeled data to train the model efficiently, supervised learning performs well. It’s an effective technique for resolving issues where precision and dependability are crucial.
What are the Key Features of Supervised Learning
Employs Labelled Data: Because it uses labeled data for training, supervised learning is unique. When a dataset is labeled, it indicates that every input has a corresponding output, or “label.” The model uses this label as a reference to help it comprehend how input features relate to the right result. Every image in a supervised learning assignment for image classification, for instance, is labeled with a word like “cat” or “dog.” Over time, the model improves its predictions by learning from these instances and modifying its internal parameters.
Acquires Knowledge of Patterns: Finding patterns in data is a fundamental aspect of supervised learning. The model starts to identify patterns and correlations between inputs and their related outputs after being trained on labeled instances. For example, the model learns the relationship between price and parameters like size, location, and number of rooms in a job like forecasting home prices. The model can generalize and forecast fresh, unknown data by identifying these patterns. In industries where precise forecasts are essential, such as marketing, healthcare, and finance, this pattern identification skill is essential for making well-informed judgements.
Needs Training: Supervised learning needs an initial training phase with labeled data in order to function. In order to “learn” the link between inputs and labels, the model is exposed to a dataset with known outcomes throughout this phase. To reduce prediction mistakes, the model modifies its underlying parameters, such as weights in a neural network. After training, the model is evaluated with fresh, untested data to assess how well it applies to actual circumstances.
What are the Types of Supervised Learning
Classification
In the supervised learning task of classification, the model uses input information to predict discrete class labels. The goal is to use a training dataset that contains inputs and their matching outputs (labels) in order to allocate data points to preset categories. For instance, a multiclass classification work can entail classifying handwritten numbers (0–9), whereas a binary classification task would entail differentiating between spam and non-spam emails.
By minimising an error metric, like cross-entropy loss, the model learns to translate input data to the appropriate class labels during training. Following training, measures like as accuracy, precision, recall, and F1 score are used to assess the model’s performance on unknown data. To increase classification accuracy, sophisticated methods like ensemble learning (e.g., random forests or gradient boosting) are frequently employed.
Regression
Regression is an alternative supervised learning problem in which the model uses input information to predict a continuous output variable. In contrast to classification, which produces categorical results, regression is concerned with forecasting numerical values. Regression analysis may be used, for example, to forecast home values according to factors like size, location, and condition.
Regression algorithms that are often employed include polynomial regression, linear regression, and more complex techniques like gradient boosting or ridge regression. The objective is to reduce the difference between expected and actual values, which is frequently quantified using metrics such as mean absolute error (MAE) or mean squared error (MSE). For activities including resource allocation, trend analysis, and forecasting, regression models are essential.
Real-World Applications of Supervised Learning
Identification of Email Spam
In email systems, supervised learning is essential because it helps weed out spam communications. This program uses a labeled dataset that includes both spam and non-spam (ham) emails to train a model. The system gains the ability to recognize particular characteristics of spam, including particular keywords, sender conduct, or message structure.
The model improves its ability to identify incoming emails over time, separating spam from authentic correspondence. Email systems can increase the accuracy of their filters by utilizing supervised learning to adjust to new kinds of spam. One of the most useful uses of machine learning is this technique, which shields consumers from dangerous information and phishing attempts while also assisting them in avoiding unsolicited emails.
Fraud Detection in Finance
Supervised learning is crucial for real-time fraud detection in the banking industry. Historical transaction data, encompassing both authentic and fraudulent transactions, is used to train models. The system gains the ability to recognize patterns like odd locations, odd transaction timings, or odd spending patterns. After training, the model may either automatically block transactions that appear suspicious or flag them for additional inspection.
Financial institutions can reduce the risks to their clients and the company by employing supervised learning to swiftly identify and stop fraud. With the growth of online payments and digital banking, this application has grown more and more significant.
Predicting Customer Behaviour
Companies frequently employ supervised learning to forecast future consumer behavior, which aids in the development of focused marketing campaigns. To forecast which goods a client is likely to purchase next, a model may be trained by examining demographic data, internet browsing patterns, and previous purchase data.
Online merchants, for instance, utilize this technique to suggest items to customers based on their past browsing or purchase activity. Over time, the model improves its ability to make precise predictions by being trained on labeled data that contains information about client behaviour. Making pertinent recommendations, not only increases revenue but also enhances client happiness.

Key Information about Supervised Learning
What Is Unsupervised Learning?
In unsupervised learning, the model is provided with data that has no labels or predetermined responses. The system looks for patterns or groups in the data on its own rather than learning from instances with established results. For instance, even if the groups aren’t labeled, it may examine a set of customer data and put like customers together according to their buying patterns. This method works well for finding hidden patterns or insights in data that others would not see, such as odd patterns, market niches, or trends. Data compression, anomaly detection, and customer segmentation are examples of jobs that frequently involve unsupervised learning.
What are the Key Features of Unsupervised Learning
Grouping Data Automatically: Unsupervised learning does not require pre-established categories to automatically cluster data. This procedure, called clustering, enables the model to identify patterns in the data, such putting clients in groups based on shared interests or habits. Based on their purchasing habits, it may, for example, divide consumers into categories such as “frequent shoppers,” “budget-conscious shoppers,” or “new customers” in a retail context. These categories might assist companies in better focussing their marketing efforts and customizing their products to meet the wants of certain clientele.
Investigates Data Relationships: Exploring the connections between various data pieces is a strength of unsupervised learning. The model can find underlying relationships that might not be immediately apparent by examining the structure of the data. The system may indicate odd data points that stand out from the rest because to this capability, which is very helpful in anomaly detection. Unsupervised learning, for instance, might identify odd activity patterns that can point to a security breach in network security, assisting in the early detection of problems.
Adaptability in the Analysis of Data: Unsupervised learning is more adaptable in managing complicated and unstructured data than supervised learning as it does not require the data to adhere to a predetermined framework. Without requiring labeled outputs, it may operate on enormous datasets that comprise a variety of data kinds, including text, pictures, and numerical values. Because of its adaptability, it is especially helpful for jobs involving complex and varied data, such as data compression, social media sentiment analysis, and consumer behavior research.
What are the Types of Unsupervised Learning
Clustering
There are several forms of unsupervised learning, each intended for a particular job or objective. Clustering, which organises data according to similarities, is one of the most used kinds. Without knowing ahead of time how many groups should be present, the algorithm attempts to identify organic groupings within the data. A business may utilise clustering, for instance, to divide its clientele into groups according to their purchasing patterns, such as “frequent buyers” or “discount shoppers.” Finding underlying patterns or trends through clustering may be helpful for a variety of purposes, including tailored suggestions and targeted marketing.
Association rule learning
Association rule learning is another kind of unsupervised learning that focusses on identifying correlations between variables in big datasets. Finding rules that explain how objects are related to one another is the aim. In the retail industry, for instance, association rule learning may show that consumers who purchase bread also frequently purchase butter. Product placement in stores can be optimised or product suggestions can be made using these information. It’s helpful in any situation when it’s critical to comprehend the relationships between several objects or behaviours.
Dimensionality reduction
another kind of unsupervised learning is called “dimensionality reduction,” which lowers the number of variables or features in a dataset while keeping the most important information. Complex datasets may be simplified using this method, which facilitates analysis and visualization. It is especially helpful in fields like image processing, where there are numerous characteristics in the data, but only a select number are significant. Dimensionality reduction increases the effectiveness of other machine learning activities by eliminating superfluous data, which facilitates the identification of patterns or abnormalities.
Real-World Applications of unsupervised Learning
Customer Segmentation
One of the most effective uses of unsupervised learning is customer segmentation. Without the requirement for pre-established categories, this method assists companies in grouping their clients according to common traits or actions. Businesses can find consumer groups with similar requirements, tastes, or purchasing habits by using clustering algorithms.
Unsupervised learning might be used, for instance, by an online store to classify consumers who often purchase particular goods, such tech devices or health and wellness products. Businesses may target particular groups with individualized discounts or promotions by knowing these client segments and adjusting their marketing strategies accordingly.
Recommendation Systems
Recommendation systems, which aim to provide consumers with content, services, or goods based on their tastes, also make extensive use of unsupervised learning. Unsupervised learning is used by streaming services like Netflix, Spotify, and YouTube to examine users’ listening or viewing patterns and suggest new material.
If a user often watches action films, for example, the system may suggest related films based on what other users with comparable tastes have seen. In order to improve the accuracy of these recommendations, unsupervised learning assists in identifying trends in user behavior. Unsupervised learning’s ability to recognize these patterns even in the absence of predetermined labels makes it flexible enough to adjust to shifting user preferences.
Market Basket Analysis
One important use of unsupervised learning, especially in retail, is market basket analysis. It entails examining consumer purchasing trends to determine which items are most commonly purchased in tandem. Unsupervised learning, which does not require pre-labeled data, assists in identifying these links through association rule learning.
For instance, store layouts may be optimized or bundled product promotions might be created if clients who frequently purchase bread also frequently purchase butter. Retailers might use this information to provide discounts on matched items or to arrange products in a way that promotes more sales. In online retail, market basket research is especially important since it may provide suggestions for items to put in the shopping cart, which boosts sales.

Key Information about Unsupervised Learning
Demystifying AI: A Comprehensive Guide to Key Concepts and Terminology
This guide will cover the essential terminology that every beginner needs to know. Whether you are a student, a business owner, or simply someone who is interested in AI, this guide will provide you with a solid foundation in AI terminology to help you better understand this exciting field.

How papAI Helps Build Effective AI-Powered Process Optimization?
papAI is an all-in-one artificial intelligence solution made to optimize and simplify processes in various sectors. It offers strong data analysis, predictive insights, and process automation capabilities.
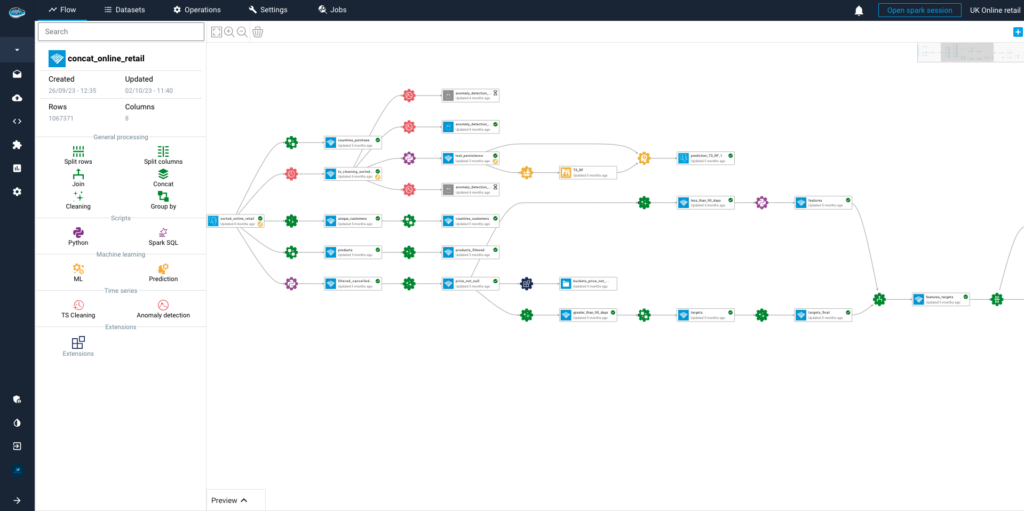
Here’s an in-depth look at the key features and advantages of this innovative solution:
Supports Labeled and Unlabeled Data
papAI is a flexible approach to supervised and unsupervised learning problems because of its ability to handle both labeled and unlabelled data with ease. Labeled data is crucial for supervised learning since it gives the model instances with input-output pairings, which are used to train the model. By efficiently handling datasets where every piece of incoming data is already categorized, papAI simplifies this procedure.
papAI, on the other hand, allows users to find hidden patterns, clusters, or correlations within the raw data for unsupervised learning when the data does not have labels. Organizations may work on a variety of use cases, including supervised fraud detection and unsupervised consumer segmentation, thanks to this dual capacity.
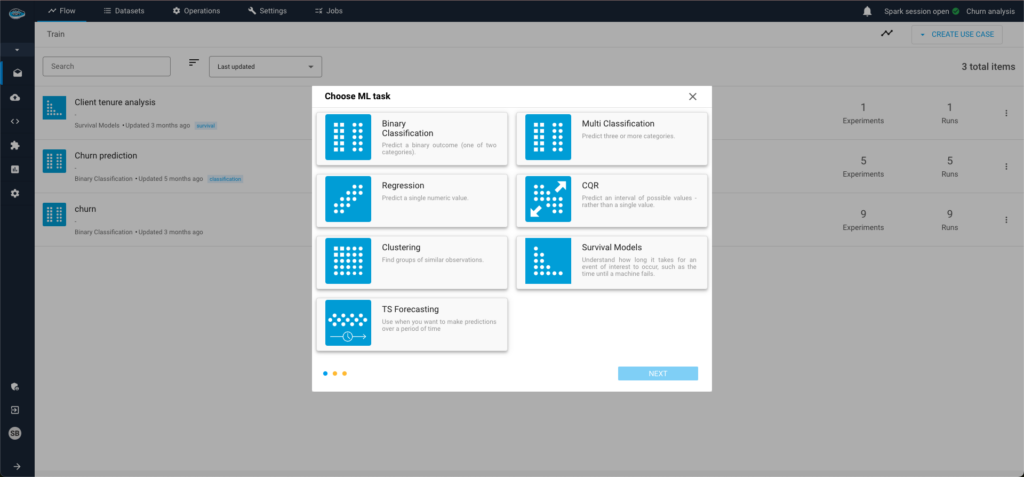
Automated Data Processing
Large dataset processing may be difficult and time-consuming, but papAI’s automated data processing features make it easier. It effectively manages raw data organization, cleansing, and analysis so users can concentrate on deriving insightful information. In order to assist in increasing the accuracy of training models for supervised learning, papAI makes sure that labeled data is adequately prepared and arranged.
Its algorithms examine unlabelled data for unsupervised learning in order to find patterns, clusters, or trends that could otherwise go overlooked. By automating these procedures, papAI speeds up the data analysis lifecycle and decreases manual effort, facilitating quicker decision-making and more efficient use of resources.
Real-time Insights
With the help of papAI’s real-time insights, businesses can act swiftly and decisively. It guarantees that organizations may react proactively to evolving situations by analyzing both labeled and unlabelled data in real-time. The real-time capabilities of papAI in supervised learning enable models to provide prompt predictions or classifications, such as identifying fraudulent transactions as they happen.
Its ability to identify irregularities or changes in patterns in real-time is essential for unsupervised learning applications such as dynamic market analysis and network security. Businesses get a competitive edge by acting quickly on data-driven knowledge thanks to these real-time insights, which also improve operational efficiency.
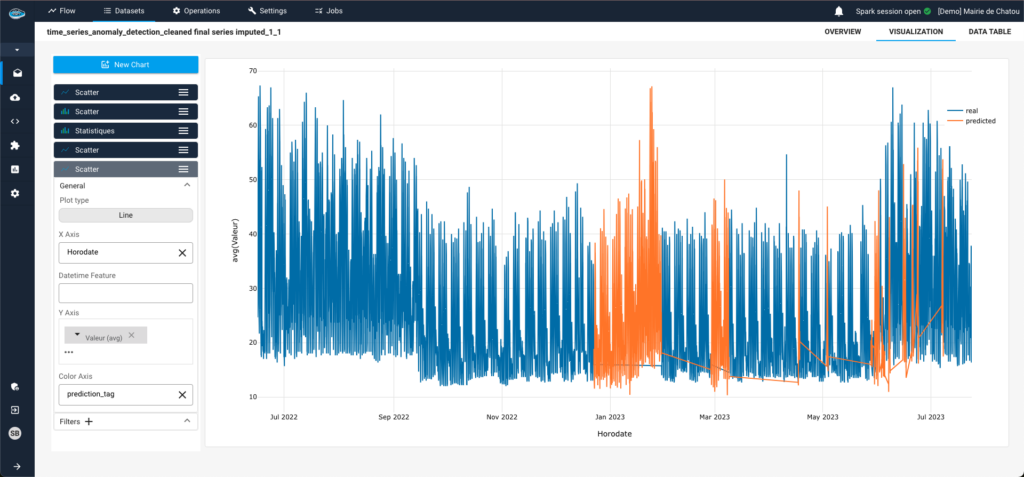

In real-world use cases, both supervised and unsupervised learning coexist. Companies must adopt the best AI tools to address their specific challenges and align with their business objectives.
Thibaud Ishacian
Head of Product - Datategy
Create your Own AI Platform to Leverage your Data using papAI solution
Leveraging AI’s capabilities is now essential for firms looking to remain ahead in the fast-paced world of today. You may use supervised learning, unsupervised learning, or a combination of both to fully use your data by building your own AI platform with papAI.
Activate Your Free Session with papAI and discover how our innovative platform can drive your success. Click now and take the first step toward building your AI-powered future!
Supervised learning uses labeled data; unsupervised identifies patterns without pre-labeled information.
By teaching relationships between inputs and outputs using labeled examples.
Grouping customers into segments based on purchasing behavior.
Classification predicts categories; regression forecasts continuous values.
Finds hidden data patterns or clusters independently.
Interested in discovering papAI?
Our AI expert team is at your disposal for any questions

Why is Deployment Speed the New 2026 AI Moat?
Why is Deployment Speed the New 2026 AI Moat? The...
Read More
We Don’t Just Build AI, We Deliver Measurable Impact
We Don’t Just Build AI, We Deliver Measurable Impact Join...
Read More
AI’s Role in Translating Complex Defence Documentation
AI’s Role in Translating Complex Defence Documentation The defence sector...
Read MoreSupervised and Unsupervised Learning: A Comparison Guide
Summary

Article Name
Supervised and Unsupervised Learning: A Comparison Guide
DescriptionDiscover the key differences between supervised and unsupervised learning. and examples and insights to choose the right approach.
Author
hocine ousmer
Publisher Name
Datategy
Publisher Logo