
Why Should You Consolidate Your AI Tools for Faster Scaling?...
Read MoreHow to Build a RAG System for Real-World Use?
Table of Contents
ToggleLarge language models (LLMs) are increasingly serving as the foundation of most organizations these days as AI becomes more and more prevalent worldwide. Indeed, LLMs can occasionally yield unexpected results, including biased or fabricated information.
The most notable strategies for reducing LLM hallucinations include retrieval augmented generation (RAG), prompt engineering, and fine-tuning. We will demonstrate the RAG approach’s operation to you today.
A study by Google AI showed that RAG models were 25% more relevant in their responses to user queries.

The Emergence of Retrieval Augmented Generation (RAG)
The development of information retrieval and natural language processing (NLP) is the foundation of retrieval-augmented generation, or RAG. Despite their advances in producing coherent text, early language models such as GPT-2 and GPT-3 were limited by their reliance on pre-existing training data.
This meant that answers might become dated or narrowly focused, particularly for inquiries about current events or specialized knowledge. Researchers started looking into ways to combine generative models with outside information sources in order to get around these problems. The goal was to lay the groundwork for RAG by enabling AI systems to “look up” real-time information during the generation process.
As RAG technology developed, more industries began to use it as search algorithms and retrieval efficiency continued to improve. To address early concerns about latency, RAG models started utilizing semantic search and advanced indexing techniques to improve retrieval speed and accuracy.
RAG is a state-of-the-art approach to developing intelligent systems that can connect the dots between static knowledge and dynamic, real-world information requirements. This allows industries to develop more resilient AI-driven applications.
What does RAG Mean?
Retrieval-Augmented Generation (RAG) is an artificial intelligence technique that combines the potent functions of text generation and information retrieval. Though they are excellent at producing text, traditional AI models such as GPT are limited by the data they were trained on, which may be dated. RAG makes this better by enabling the model to get the most recent data from outside sources, such as websites or databases, before producing a response. In this manner, the AI uses up-to-date, pertinent data rather than merely speculating or depending on outdated information.
The Core Components of a RAG System
The Retrieval Model: What It Does and Why It Matters
When an AI needs to provide an answer, the retrieval model in a Retrieval-Augmented Generation (RAG) system finds and brings in the most pertinent information. The retrieval model actively searches external data sources, such as documents, databases, or even the web, to find information that fits the query, in contrast to typical AI models that rely only on what they have been trained on. Consider it as the AI’s equivalent of a potent search engine. This procedure makes sure that before the system even starts to generate a response, it has the most recent and accurate information.
The Generative Model: Adding Intelligence to Responses
After the pertinent data has been retrieved, the generative model in a Retrieval-Augmented Generation (RAG) system is in charge of producing responses that resemble those of a human. The generative model takes information and transforms it into responses that are clear and sensitive to context, in contrast to the retrieval model, which concentrates on finding information. In order to “understand” the context of the input and produce text that is appropriate for the task or conversation, it employs machine learning techniques, which are frequently based on pre-trained models like GPT or BERT. In essence, it is the component of the system that endows the responses with intelligence and fluidity, elevating them above the status of mere factual outputs.
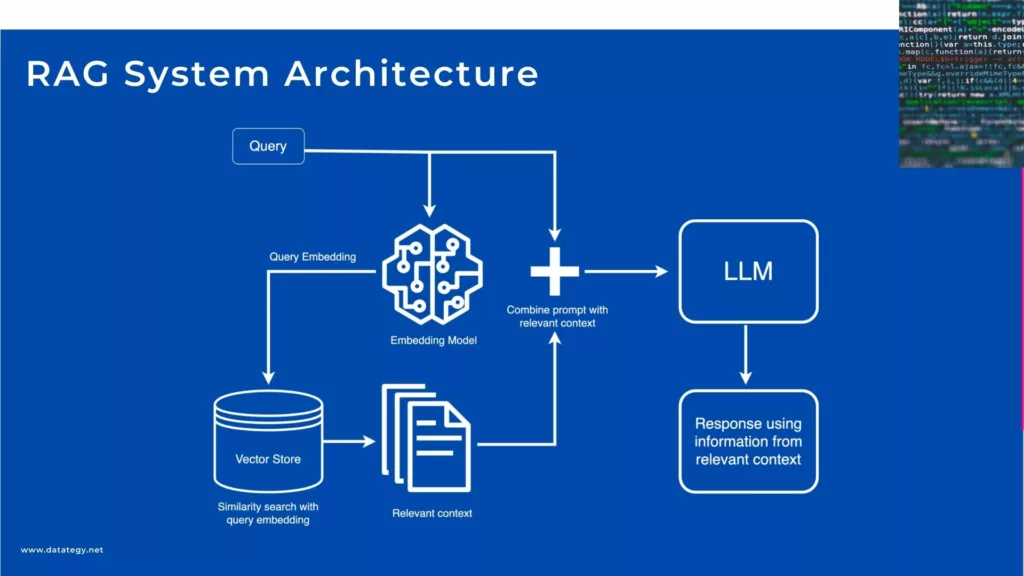
RAG System Architecture
How do we Implement RAG System within the Organization?
Data Preparation
The quality and relevance of the data that a Retrieval-Augmented Generation (RAG) system retrieves are critical to its success. The right data must be gathered in order for the system to produce responses that are accurate and meaningful. This may originate from a number of places, including publicly accessible datasets, corporate knowledge bases, or even data that has been scraped from websites. It’s crucial to consider the type of data your RAG system will require in order to respond to inquiries and complete tasks and to collect that data. For instance, you should incorporate product manuals, FAQs, and previous customer interactions into your chatbot when developing a customer support system.
Cleaning and organizing the data is an essential next step after it has been gathered. Duplicate data, mistakes, and missing information are common in raw data, which can confuse the retrieval model and produce subpar results. Duplicate entry removal, incomplete entry filling or deletion, and format standardization are examples of data-cleaning tasks. For example, you may need to make sure that all the dates in a dataset of customer feedback have the same format or that terms that are similar to one another, like “buy” and “purchase,” are interpreted similarly when conducting searches. This stage makes sure the data is consistent and prepared for the retrieval model to process it effectively.
Build the Retrieval Component
One of the most important parts of a RAG system is building the retrieval component, which manages the process of retrieving pertinent data that the generative model will use to generate responses.
As you begin to build this component, you should consider how your system will find and obtain the required data. You can choose from different retrieval techniques, such as keyword-based searches or more advanced semantic searches that understand the meaning behind words. This choice is based on the kinds of queries that your system will handle. Semantic search techniques are superior for more complex and nuanced questions, whereas keyword searches are ideal for straightforward and simple queries.
Properly indexing your data is the next step after selecting your retrieval method. Indexing helps the system find the right information more quickly by acting as a map or catalog for your data. Several algorithms that build indexes based on words, phrases, or even semantic relationships between data points can be used to accomplish this.
Set Up the Generative Model
Using pre-trained models like GPT or BART is a good place to start when implementing a generative model. These models are easily found in well-known libraries, such as Transformers by Hugging Face. Their purpose is to process input data and generate linguistic responses that are natural-sounding and coherent. Because of this, they can be used for a wide range of tasks, such as producing interesting content and responding to inquiries.
Integrating your selected model with your retrieval system is the next step. In order to generate responses, the model must be connected to the data. When working on a customer service application, for example, the retrieval model can pull pertinent data from a knowledge base, and the generative model can transform that data into an insightful response. Because the generative model can modify its responses in response to the retrieved data, this combination enables a more dynamic interaction.
Link the Generative and Retrieval Models
The real magic of AI is revealed when retrieval models and generative models work together harmoniously. The retrieval model is central to this process, helping to identify pertinent data from large datasets. It finds passages of text, documents, or responses by searching through vast archives of data that are directly related to the user’s query. This feature not only makes the data more relevant, but it also creates the ideal environment for the generative model to unleash its creative potential.
Feeding this curated data into the generative model is the next step after the retrieval model completes its task. At this point, the generative model steps in and synthesizes the data that was retrieved to create a response that makes sense and fits the context. But this isn’t just a plug-and-play procedure—careful fine-tuning is frequently needed. To correctly interpret the retrieved data and seamlessly incorporate it into its responses, the generative model needs to be trained. This guarantees that the finished product will be both educational and have a tone that is both engaging and natural.
Deploy the RAG System
Once you’re satisfied with the system’s performance, deploying your retrieval-augmented generation (RAG) system is an exciting next step. For preliminary testing, you can either scale it up for production use or set it up in a local environment. If you go with the latter, you can get the resources you need to support your system efficiently by using a server or cloud-based infrastructure such as AWS or Google Cloud. This guarantees that your RAG system is robust enough to manage a range of workloads in addition to being functional.
As you get ready for deployment, make sure your system is capable of effectively handling requests in real-time. To provide users with a positive user experience, entails optimizing response time. Using the appropriate monitoring tools will also enable you to keep tabs on the system’s operation and spot any potential problems. By taking a proactive stance, you can keep your RAG system operating smoothly and respond quickly to issues.
A to Z of Generative AI: An in-Depth Glossary
A form of artificial intelligence called “Generative AI” enables machines to produce text, pictures, and music on their own. By automating activities, improving customization, and encouraging innovation, it is revolutionizing industries by using the power of algorithms and deep learning. This guide will provide you with a solid foundation in Gen AI terminology to help you better understand this exciting field.

Real-World RAG Implementation: Use Cases
Customer Support Automation
Retrieval-Augmented Generation (RAG) systems for customer support automation have transformed how businesses communicate with their customers. Customers may get prompt answers to their questions rather than waiting for a human agent. The RAG system promptly obtains pertinent data from a database of FAQs, manuals, and troubleshooting documents when a customer contacts it for assistance. This indicates that in addition to being prompt, the response is accurate and founded on solid data.
Furthermore, by customizing these responses to the unique requirements of the client, the generative model improves them. When a consumer enquires about a product’s features, for example, the RAG system can provide a customized response that includes relevant details and extra context. Customers benefit greatly from this because they feel heard and supported. In the end, this automation lessens the workload for human agents, freeing them up to concentrate on more complicated problems while still making sure that simple queries are answered quickly.
Content Generation
Writers and marketers are finding RAG systems to be useful resources in the field of content generation. These systems can assist content creators in gathering data on trending subjects, important statistics, and current events by retrieving information from a variety of sources. This implies that someone can easily obtain all the information they need without spending hours researching when they are assigned to write an article or a blog post.
Then, by assisting in the creation of the content itself, the generative model goes one step further. It can transform the gathered information into a coherent draft, giving the writer a strong base on which to develop. This ensures that the content is relevant and well-informed, which not only expedites the writing process but also fosters creativity. Because the RAG system takes care of the labor-intensive tasks of obtaining information and preliminary draughting, writers are free to concentrate on honing their concepts and finding their voice.
Real-Time Decision Support Systems
RAG systems are significantly influencing decision-making in the healthcare industry. The challenge of needing immediate access to the most recent research, treatment plans, and patient data frequently faces medical professionals. RAG systems make sure healthcare professionals have access to the most recent information by retrieving pertinent medical literature and guidelines in real-time.
The generative model can evaluate the retrieved data and provide suggestions for treatment when a physician is presented with a complex case. This improves patient safety and care quality in addition to helping clinicians make well-informed decisions. RAG systems allow medical staff to focus more on their patients and less on finding information, which improves patient outcomes in the long run.
What's the Future of RAG?
What is Agentic RAG?
Agentic RAG= Agent-based RAG implementation
Agentic RAG introduces a novel agent-based framework that fundamentally changes the way we approach answering questions. In contrast to conventional approaches that exclusively depend on large language models (LLMs), agentic RAG uses intelligent agents to address difficult problems that call for careful planning, sequential reasoning, and the use of outside tools.
These agents function as expert researchers, deftly navigating through numerous documents, comparing data, producing summaries, and providing thorough and precise responses. A scalable implementation is produced by agentic RAG. It is possible to add new documents, and a sub-agent oversees each new set.
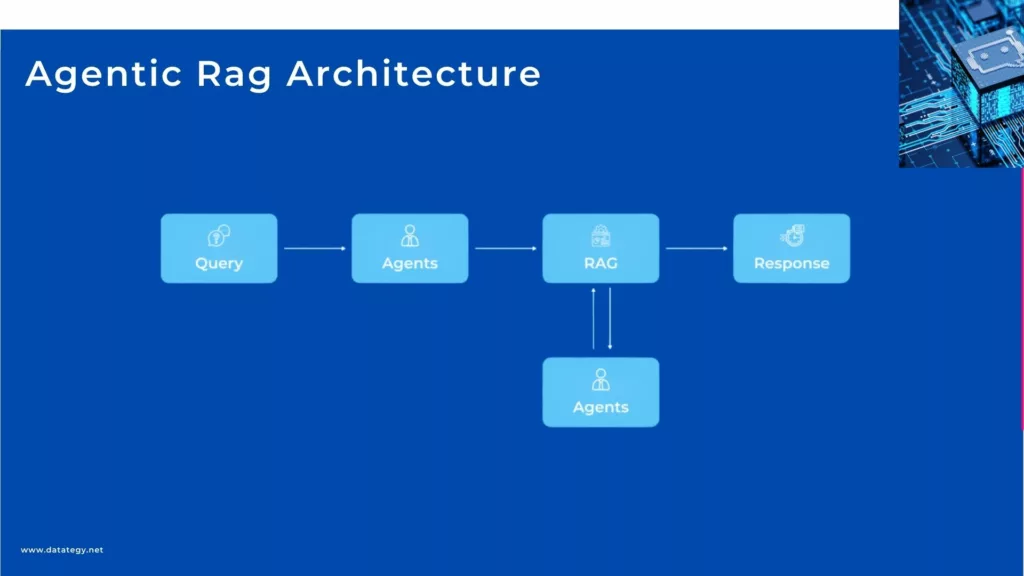
Agentic Rag Architecture
How to Choose the Right Platform to Create and Deploy your RAG
Overview of papAI 7
papAI is a comprehensive AI solution designed to facilitate the seamless deployment and scaling of data science and AI projects by businesses. papAI was created with teamwork as its primary focus. It enables groups to collaborate effectively on a single platform, simplifying challenging jobs and optimizing workflows.
It provides a comprehensive set of tools, including sophisticated machine learning methods, model deployment choices, data visualization, exploration, and robust data cleaning capabilities—all conveniently located in one location. Organizations can take on their most difficult projects with PapAI and maintain their agility and competitiveness in the rapidly changing AI market.
No-Code & Low-Code Approach
Primarily, papAI offers an intuitive interface that streamlines the entire process of creating and maintaining RAG models. The platform is easy to use even for non-technical users, so a wider range of users—from startups to well-established businesses—can access it. Teams can concentrate on improving their applications instead of getting bogged down in intricate details thanks to this ease of use.
The Power of Scalability
Scalability is considered in the design of papAI. The platform easily adjusts to your needs, regardless of whether you’re starting with a small project or hoping to scale up for large-scale production use. papAI guarantees that your RAG system can manage variable loads of real-time requests without sacrificing performance by employing cloud-based infrastructure. Businesses that expect growth or varying user demand must benefit from this flexibility, which makes it easy for them to reallocate resources as needed.
Real-time Monitoring & Continuous Improvement
Robust monitoring and continuous improvement features are highlighted by papAI platform. The performance of their RAG system can be easily tracked by users, who can learn about response accuracy, user engagement, and areas for improvement. Teams can efficiently iterate on their models and make data-driven decisions thanks to this integrated analytics capability. By selecting papAI, businesses get not only a potent RAG deployment tool but also guarantee that their systems continue to function well and be relevant in a constantly evolving digital environment.
Build your own Rag System to Meet your Specific Needs
By building your own Retrieval-Augmented Generation (RAG) system, you can customize the technology to fit your unique requirements and goals. You can make sure your RAG model retrieves the most pertinent data and produces responses that precisely match the objectives of your company by customizing it.
See how a RAG system can be tailored to your requirements by scheduling a demo to see papAI in action. Our platform provides the resources and assistance required to design a personalized RAG solution that blends in perfectly with your operations. Set up a demo with papAI right away to discover how it can benefit your company and don’t pass up the chance to improve engagement and operations!
Interested in discovering papAI?
Our AI expert team is at your disposal for any questions

Why is Deployment Speed the New 2026 AI Moat?
Why is Deployment Speed the New 2026 AI Moat? The...
Read More
We Don’t Just Build AI, We Deliver Measurable Impact
We Don’t Just Build AI, We Deliver Measurable Impact Join...
Read More
AI’s Role in Translating Complex Defence Documentation
AI’s Role in Translating Complex Defence Documentation The defence sector...
Read MoreHow to Build a RAG System for Real-World Use?
Summary

Article Name
How to Build a RAG System for Real-World Use?
DescriptionFocuses on RAG systems from prototypes to production-grade applications with attention to scalability, reliability, and architecture.
Author
hocine ousmer
Publisher Name
Datategy
Publisher Logo