
How RAG Systems Improve Public Sector Management The most important...
Read More

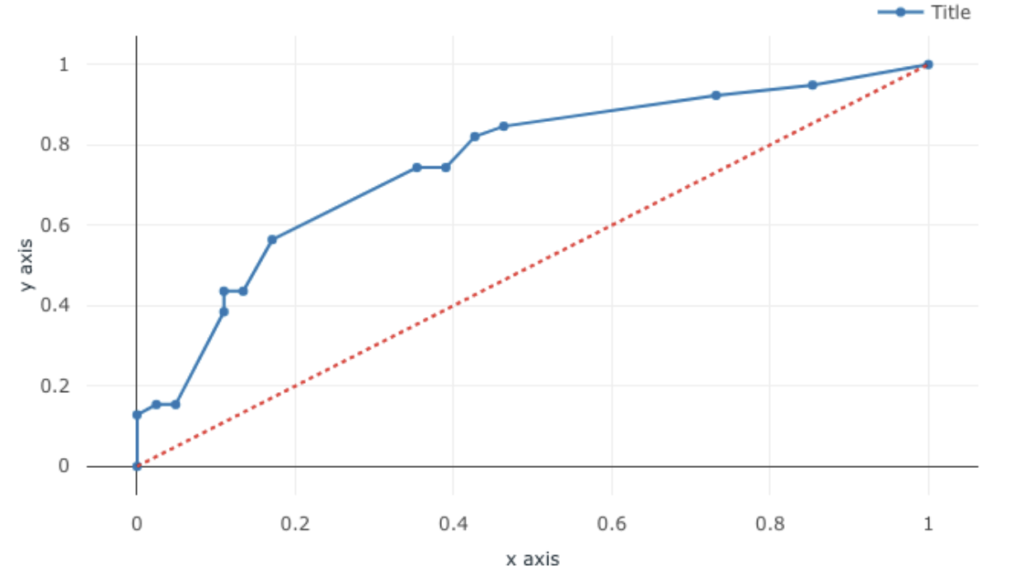
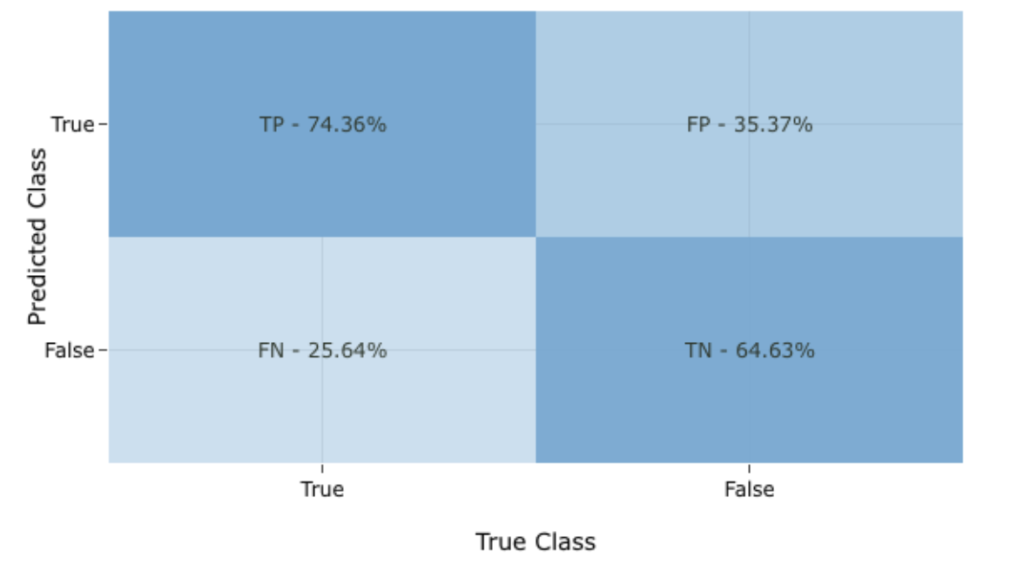
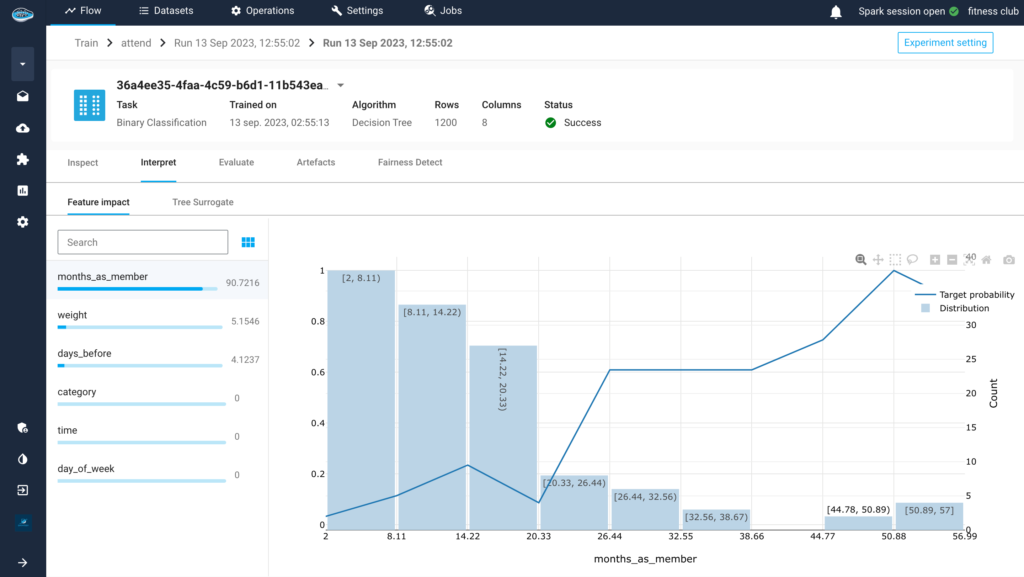
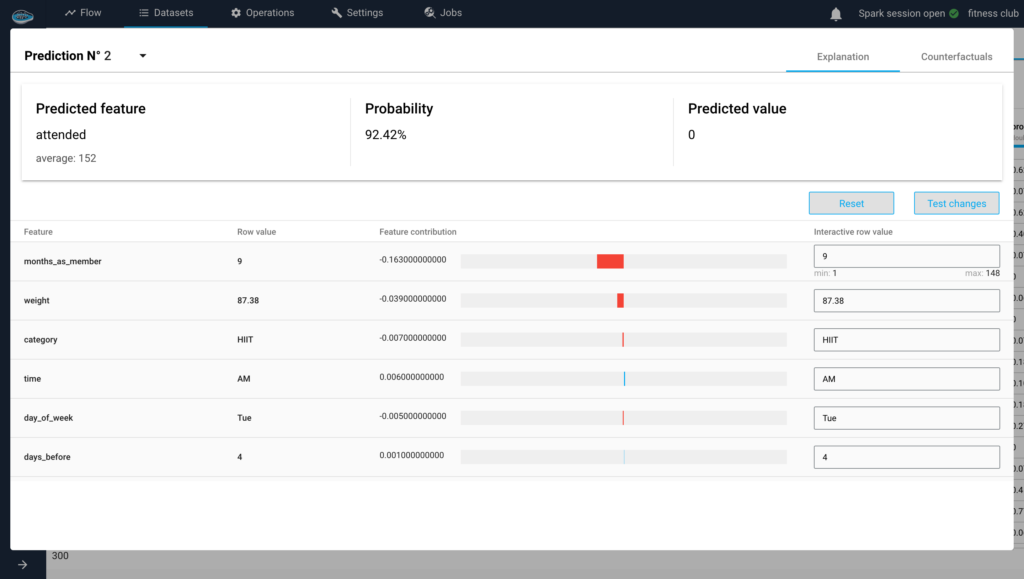

Scaling RAG Systems in Financial Organizations
Scaling RAG Systems in Financial Organizations Artificial intelligence has emerged...
Read More
How AgenticAI is Transforming Sales and Marketing Strategies
How AgenticAI is Transforming Sales and Marketing Strategies Agentic AI...
Read More
“DATATEGY EARLY CAREERS PROGRAM” With Abdelmoumen ATMANI
“DATATEGY EARLY CAREERS PROGRAM” With Abdelmoumen ATMANI Hello, my name...
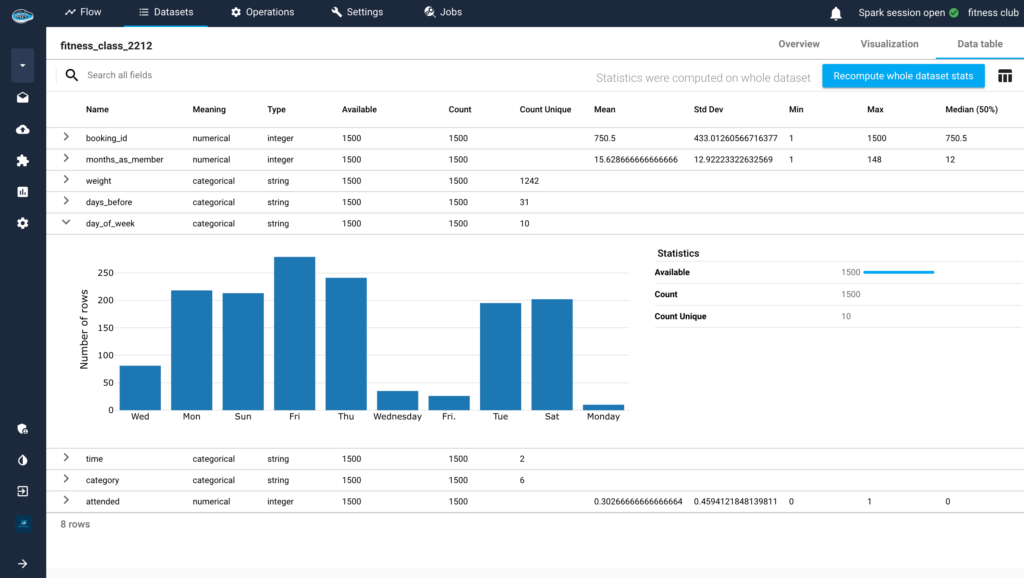
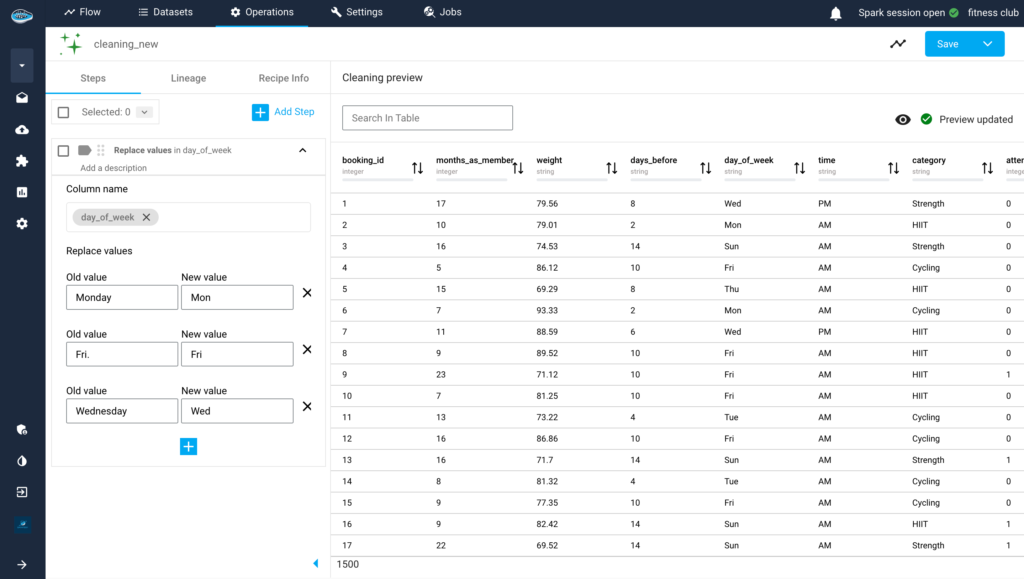
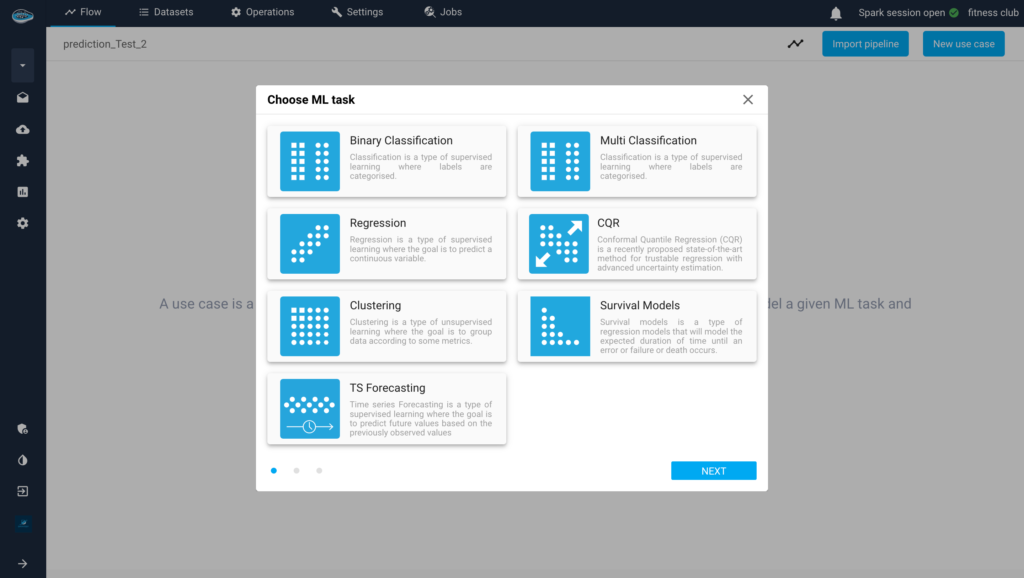
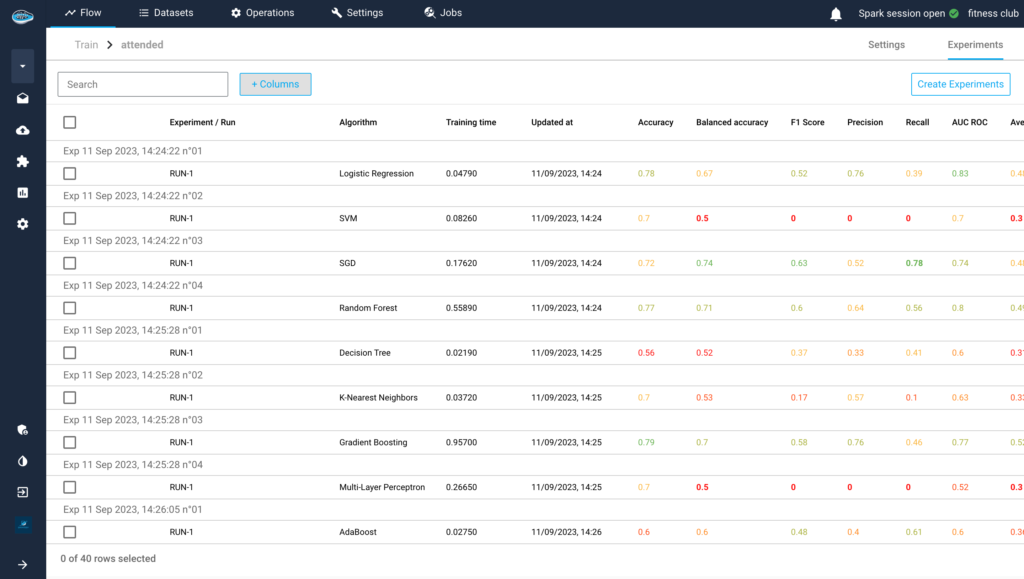
Read MorepapAI 7 in Action: Predictive Member Attendance for Fitness Clubs