
How Law Firms Use RAG to Boost Legal Research RAG...
Read More

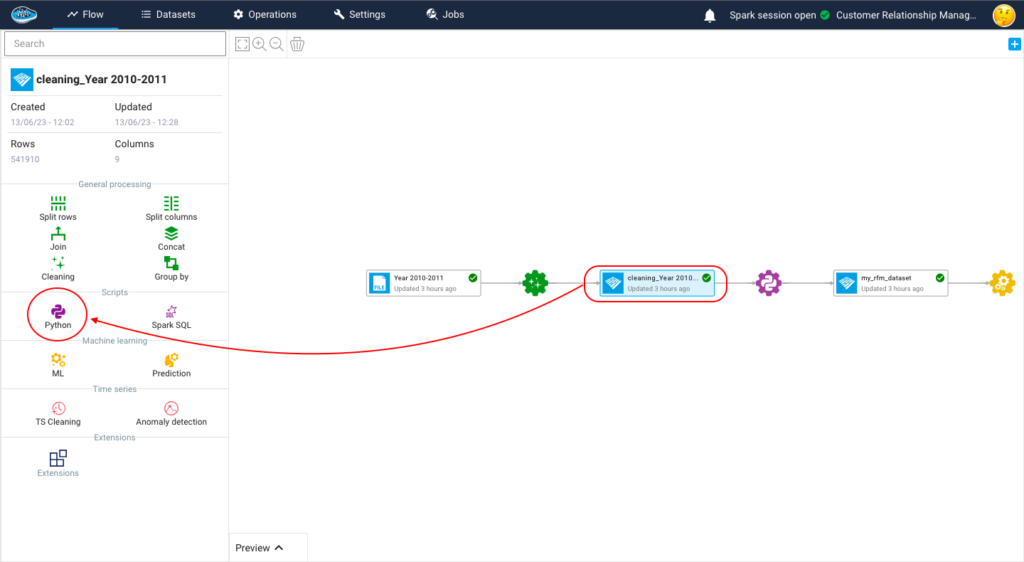
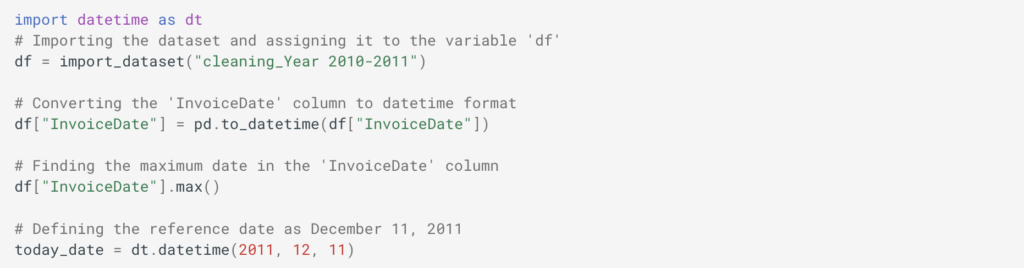
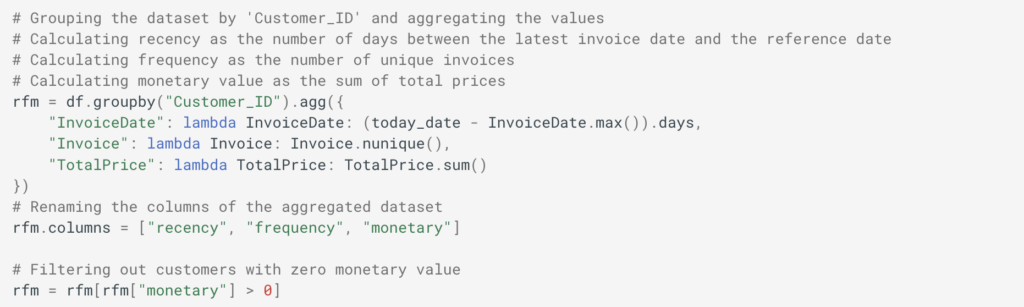

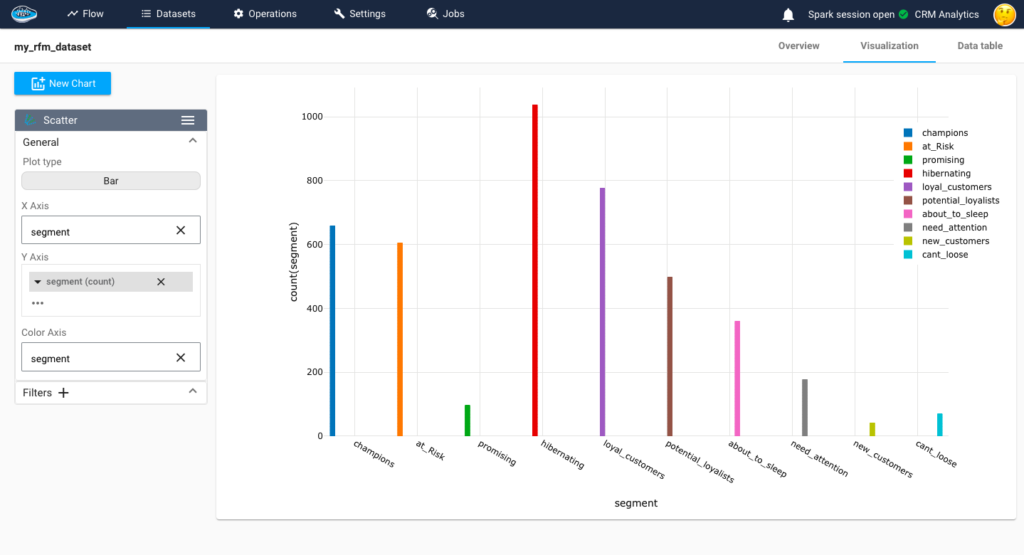

How RAG Systems Improve Public Sector Management
How RAG Systems Improve Public Sector Management The most important...
Read More
Scaling RAG Systems in Financial Organizations
Scaling RAG Systems in Financial Organizations Artificial intelligence has emerged...
Read More
How AgenticAI is Transforming Sales and Marketing Strategies
How AgenticAI is Transforming Sales and Marketing Strategies Agentic AI...
Read MoreUnleashing the Power of Personalization: How Machine Learning is Transforming Customer Segmentation to Improve Marketing Strategy?