
Why Should You Consolidate Your AI Tools for Faster Scaling?...
Read MoreOptimize RAG Systems Like a Pro with Fine-Tuning
Table of Contents
ToggleAs artificial intelligence (AI) grows more and more commonplace globally, large language models (LLMs) are increasingly being used as the cornerstone of most organizations. In retrieval augmented generation (RAG) the fine-tuning process is the right approach to leverage all the potential of these systems.
In Retrieval Augmented Generation (RAG), the fine-tuning process is the right approach to exploit the full potential of these systems according to all the experts because it allows us to transform general knowledge into more intelligent and specific intelligence. Fine-tuned Rag are better at handling complex sentence structures, maintaining coherence throughout longer passages, and minimizing common issues.

In this article, we will explore the challenges in standard RAG implementations and the right Fine-Tuning Strategies for it.
What is meant by RAG?
The advancement of natural language processing (NLP) and information retrieval forms the basis of retrieval-augmented generation, or RAG. While early language models like GPT-2 and GPT-3 made progress in creating intelligible text, their limitations stemmed from their dependence on pre-existing training data.
In natural language processing (NLP), retrieval-augmented generation (RAG) is an advanced technique that blends the advantages of text creation and information retrieval. RAG essentially combines a generator that creates logical and contextually appropriate replies with a retriever that looks for and chooses the most pertinent information from external data sources.
This combination enables RAG models to generate correct and context-aware responses or content, which makes them perfect for jobs like conversational AI, summarisation, and question-answering.
What is the Importance of Fine-Tuning in RAG
Improved Retrieval Accuracy: The retriever component is essential to RAG since it helps choose the most pertinent information from a wide range of external knowledge sources, including databases and document corpora. By modifying its weighting algorithms and ranking strategies, the retriever may be fine-tuned to better match query patterns to the most relevant bits of information.
This is accomplished by honing the model’s capacity to discriminate between documents of high and low relevance using techniques like contrastive learning and supervised retriever training. The system’s capacity to weed out irrelevant results and retrieve information that more precisely answers user queries is enhanced as the retriever gets more specialized via fine-tuning.
Enhanced Domain Accuracy: By adjusting its pre-trained components to domain-specific data, an RAG system may be fine-tuned to allow the model to specialize in a certain area. This is essential for jobs like legal, medical, or financial situations that call for extremely precise answers based on specialized expertise. Fine-tuning enhances the system’s capacity to identify and retrieve data relevant to the particular domain by introducing domain-related terminology, technical jargon, and real-world events into the training process.
This focused modification guarantees that the model provides insights based on the pertinent body of information rather than generalized answers. Supervised learning, in which the model is trained on labeled datasets that include examples of the particular tasks the system is expected to do, is frequently used to accomplish domain-specific fine-tuning.
Increased Output Coherence: In a RAG system, the generator is in charge of converting the information that has been gathered into coherent, contextually relevant prose that is accessible by humans. Improving the generator component’s capacity to provide fluid, context-sensitive outputs based on the data obtained is the main goal of fine-tuning it.
Typically, fine-tuning techniques entail training the generator on task-specific datasets that comprise a variety of response-generating formats, including conversational dialogues, summaries, and structured replies. Through this process, the language model is improved to better comprehend the subtleties of the work at hand and generate outputs that are consistent with the retrieval context and the user’s purpose.
What are the Key Components of a RAG System?
Embedding Models
A key element of RAG systems are embedding models, which convert unprocessed text into dense vector representations that let computers comprehend and work with the meaning of words and phrases. By capturing the semantic linkages between words, these embeddings make it possible to generate and retrieve pertinent information quickly. Choosing an embedding model that is appropriate for the particular job at hand is crucial.
For example, models such as BERT or GPT are frequently employed due to their capacity to provide contextual embeddings of superior quality. By fine-tuning these models on task-specific data, retrieval accuracy and response relevance are increased as they reflect the subtleties of the domain.
Retrievers Systems
As the initial stage of the RAG pipeline, the retriever in a RAG system is in charge of finding and retrieving pertinent information from a large corpus of data. The two primary techniques that retrievers usually employ are sparse retrieval and dense retrieval. Keyword matching is the foundation of sparse retrieval, such as BM25, which is perfect for extensive document searches when speed is a top concern.
Conversely, dense retrieval matches semantic meaning with learnt embeddings, which improves its ability to capture query context and subtlety. Because it immediately affects the quality of the answer produced by the next generation, the retriever’s capacity to choose pertinent, high-quality data is essential to the system’s overall effectiveness.
Generators
In a RAG system, the generator is in charge of turning the pertinent data that the retriever has obtained into grammatically sound, contextually appropriate, and human-readable text. When handling complicated questions or lengthy information, a high-performing generator is essential to guaranteeing that the RAG system generates results that seem genuine.
Large language models, like GPT or T5, are commonly used by generators to produce text depending on the data they have gathered. These models can be adjusted to more effectively handle particular output kinds, such as producing discussions, summarising papers, or responding to inquiries.
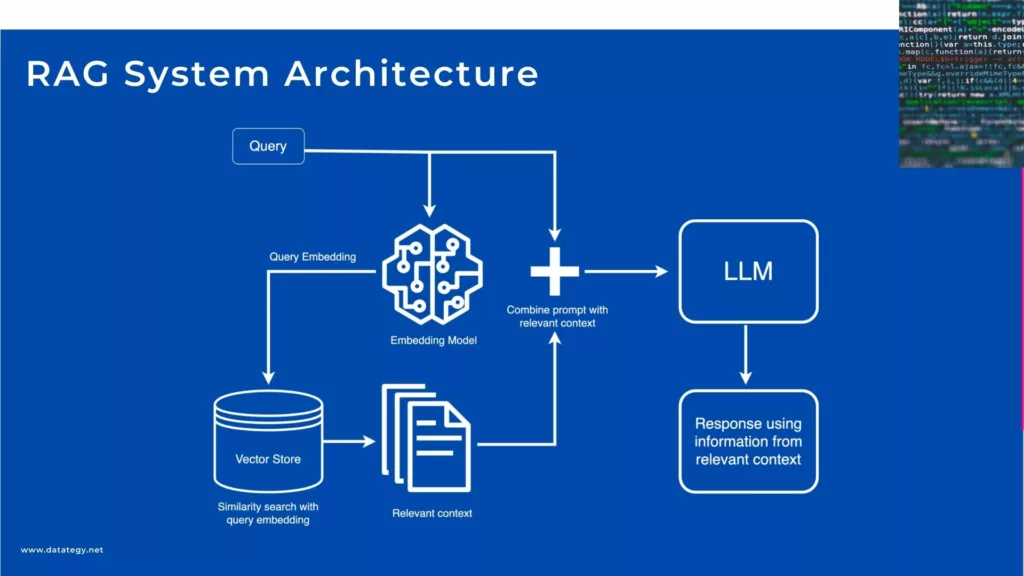
RAG System Architecture
What are the Metrics for Rag Assessment?
Accuracy
A key performance indicator for RAG systems is accuracy, which gauges how well the system generates accurate and truthful data. The system’s capacity to get pertinent data and produce outputs that satisfy the demands of the query is referred to as accuracy in the context of RAG.
For example, in activities involving answering questions, an accurate RAG system must, using the data obtained, give the user’s inquiry the exact or most correct response. Assessing accuracy frequently entails contrasting the system’s output with a collection of reference or ground truth answers, which might be from reliable sources or manually labeled datasets.
Coherence
The logical flow and consistency of the output produced by a RAG system are referred to as coherence. It evaluates the generated response’s comprehensibility at the sentence level and throughout the output. Because the generator must combine many bits of information that the retriever has gathered into a single, contextually coherent answer, coherence is particularly crucial in RAG.
An incoherent answer may cause the user to get confused or draw unrelated conclusions. Assessing coherence entails looking at the resulting text’s clarity and organization, determining whether concepts make sense together and whether the answer seems coherent and natural.
Relevance
Relevance measures how well the data produced and retrieved by a RAG system matches the user’s purpose or query. This statistic is essential for making sure the system delivers relevant and actionable information instead of irrelevant or superfluous material. Relevance in RAG systems refers to both the generator’s ability to provide an output that directly meets the demands of the user and the retriever’s ability to extract the most relevant information from the corpus.
A relevant response in a customer service application, for instance, would address the user’s query immediately without straying into irrelevant subjects. User input, human assessment, or comparison to domain-specific relevance benchmarks are the usual methods used to evaluate relevance.
Five Fine-Tuning Strategies for RAG Components
Fine-tuning Embedding Models with Domain Specificity in Mind
Optimizing a RAG system for certain activities or sectors requires fine-tuning embedding models for domain specialization. The purpose of embedding models is to transform textual input into dense vector representations that capture word associations and semantic meanings. Pre-trained models, such as BERT or GPT, are less useful for specialized applications that ask for domain-specific expertise since they are usually trained on huge, generic datasets.
By exposing these models to a smaller, domain-specific corpus, fine-tuning helps close this gap by enabling them to more accurately represent the vocabulary, subtleties, and context of the subject. Optimizing embedding models guarantees that the system can comprehend and interpret domain-specific language, whether in the fields of healthcare, finance, or law. This enhances the precision of information retrieval and the caliber of the generated outputs
Supervised learning is used in the fine-tuning step when a labeled dataset pertinent to the particular domain is used to train the model. These might be legal documents for a task involving the law or medical research articles for a healthcare application. The model’s parameters are changed during fine-tuning in order to better reflect the context and vocabulary semantics of the domain.
The embedding model would, for instance, learn to distinguish between phrases like “symptom” and “disease,” comprehending their links and contextual relevance in the medical domain. The model performs better overall on tasks like question answering, information extraction, and summarisation when it concentrates on domain-relevant data because it gets more adept at identifying subtle patterns in the language.
Direct Preference Optimization (DPO)
To enhance a model’s performance on a particular job, Direct Preference Optimisation (DPO) is a fine-tuning technique that focusses on learning a preference function. The sharpness of the preference learning aim is adjusted by the preference temperature parameter introduced by DPO, in contrast to conventional fine-tuning methods that only use loss minimization over labeled datasets.
The degree to which the model favors some outputs over others can be adjusted by researchers using this parameter. When it comes to text creation or ranking systems, for example, DPO can adjust the model to better match the intended results by learning to favor particular kinds of replies. This makes it especially helpful for jobs like recommendation systems and conversational AI that call for subjective or nuanced judgments.
By comparing outputs, DPO iteratively enhances the model’s preference for task-aligned outcomes. In recommendation systems, for example, the model may be tuned to give precedence to outcomes that are both contextually relevant and correct. This method guarantees that the behaviour of the model is closely matched with certain goals, improving its applicability and task performance as a whole. Developers may better control the model’s outputs and make more focused and precise optimizations by utilizing DPO.
Low-Rank Adaptation (LoRA)
A fine-tuning technique called Low-Rank Adaptation (LoRA) makes it possible to alter big pre-trained models in an effective and scalable manner. LoRA adds tiny, trainable low-rank matrices to the network in place of changing the whole set of model parameters. Only a portion of the parameters are changed by these matrices, enabling task-specific customization while maintaining the majority of the model’s initial weights.
LoRA is a great option for modifying large models like GPT or BERT to fit specialized domains because of its selective parameter adjustment, which lowers computational overhead and lowers the chance of overfitting. For example, LoRA preserves the broad knowledge of the original model while concentrating primarily on domain-relevant modifications when fine-tuning a language model to specialize in legal or scientific material.
LoRA allows fine-tuning even in contexts with limited resources without compromising accuracy or performance since it is lightweight, resource-efficient, and effective.
Improved Vector Search in RAG Systems
A key component of the retrieval system in a RAG (Retrieval-Augmented Generation) architecture is vector search, also known as semantic search. This part is in charge of finding and collecting pertinent facts from big external knowledge bases, giving the language model the context it needs to produce outputs that are precise, logical, and contextually correct. Vector embeddings, which are high-dimensional numerical representations of words, phrases, or documents that capture their semantic meaning rather than simply their surface-level keywords, are used by the retrieval system to do this.
Using an embedding model, such BERT or sentence transformers, the system first converts a query into a vector representation in vector search. The context, subtleties, and intended meaning of the question are all captured in this vector. A database of pre-computed vectors from texts, articles, or knowledge bases is then compared with this query vector by the retrieval system.
The algorithm ranks and returns the most pertinent texts or passages that closely match the semantic meaning of the query by utilizing similarity metrics like dot product or cosine similarity. This makes it possible for the retrieval system to take into consideration the deeper meanings and relationships between phrases in addition to keyword matching.
Enhancing Generators for Contextual Relevance
Fine-tuning a generator on task-specific data is essential to improving it for contextual relevance. It is necessary to expose the model, which is frequently built on sizable pre-trained architectures like GPT or T5, to a range of example scenarios pertinent to the field in which it will be employed. For example, a dataset of previous client questions and answers might be used to improve the generator in a customer support program.
This enables the model to learn how to respond to various client problems, decipher the subtleties of inquiries, and produce useful and contextually relevant answers. The model gains a better understanding of domain-specific scenarios, specialized vocabulary, and the subtleties of tone or formality required in the outputs through fine-tuning.
Adding features that enable the generator to concentrate on the most pertinent data that the retrieval system has collected is another crucial tactic for improving it. The generator should be taught to recognize and highlight the most important elements of the retrieved information, rather than merely producing text based on a general context.
In order to keep the answer on topic and prevent it from veering into irrelevant or peripheral material, this may include making use of attention mechanisms, which enable the generator to “attend” to particular portions of the input more forcefully. Furthermore, the generator’s replies may be guided to adhere to predetermined patterns by using structured prompts or templates, which enhances coherence and relevancy.

Fine-tuning is the key to unlocking a RAG system’s full potential, ensuring precision, relevance, and contextual accuracy by adapting the model to specific tasks and domains.
Kenneth EZUKWOKE
Data Scientist
When to Use RAG Systems?
The size of the business and its unique requirements frequently determine whether or not to deploy a Retrieval-Augmented Generation (RAG) system. RAG systems may be quite useful for small and medium-sized businesses (SMEs) that work with a variety of manageable datasets. Due to a lack of resources or fewer staff, these companies frequently struggle to obtain pertinent information quickly.
SMEs may improve processes like internal knowledge management, report preparation, and customer assistance by automating information retrieval using a RAG system. A RAG system is a viable option for businesses in this size range seeking to optimize operations as it integrates domain-specific knowledge bases to provide cost-effective scalability without requiring sizable teams of data scientists.
The huge amount of data that big businesses handle makes the usage of RAG systems much more alluring. Businesses in sectors like retail, healthcare, and finance frequently need to process enormous volumes of both structured and unstructured data in real-time. By enabling these businesses to collect and produce contextually relevant information, RAG systems guarantee that workers and clients receive precise and timely results.
Large organizations also gain from RAG’s smooth integration with current knowledge management systems, which lowers workflow bottlenecks. RAG systems are a great option for businesses wishing to improve decision-making, maximize operational effectiveness, and raise the general caliber of services due to their scalability.
A to Z of Generative AI: An in-Depth Glossary
This guide will cover the essential terminology that every beginner needs to know. Whether you are a student, a business owner, or simply someone who is interested in AI, this guide will provide you with a solid foundation in AI terminology to help you better understand this exciting field.

How papAI Helps you to Build Rag Systems ?
papAI is an all-in-one artificial intelligence solution made to optimize and simplify processes in various sectors. It offers strong data analysis, predictive insights, and process automation capabilities.
Here’s an in-depth look at the key features and advantages of this innovative solution:
Optimizing Document Retrieval
papAI-RAG combines papAI’s sophisticated ETL capabilities for preprocessing with an improved asynchronous vector database search, enabling a powerful dual-approach system for seamless retrieval. papAI’s modular workflow would handle chunking and indexing while maintaining clear data lineage with its hyper-layered approach that enables multi-granularity search across different data levels.
The key benefits include significantly faster retrieval times (64.5% latency improvement), better data quality through papAI’s preprocessing, and more comprehensive search results through the combined retrieval methods.
Response Generation
the combines papAI-RAG leverages papAI’s data validation and quality control features alongside advanced weighted reciprocal rank fusion and reranking methods for context selection and response generation. Benefits include reduced hallucination rates, improved response relevance, better explainability through visualizations, and a 66.6% reduction in energy consumption compared to traditional RAG approaches.
Workflow/Use-Case Alignment
Our RAG pipeline features customizable workflows and MLOps with a state-of-the-art efficient RAG caching mechanism for resource management. This would allow organizations to tailor the system to their specific needs while maintaining high performance and efficiency.
Benefits include reduced operational costs through intelligent resource allocation, improved workflow customization, comprehensive monitoring capabilities, and better scalability through papAI’s enterprise-ready features, all while maintaining the enhanced retrieval accuracy demonstrated by superior factuality metrics.
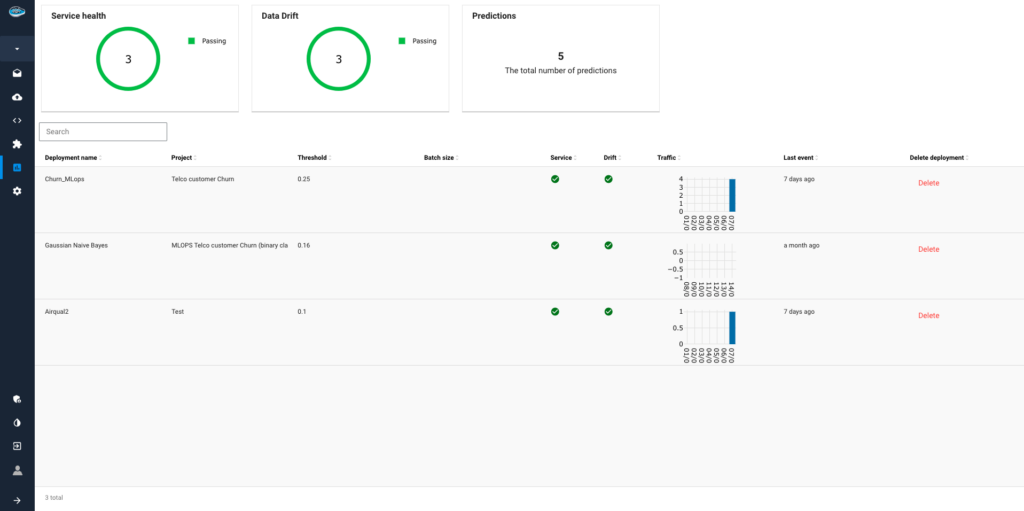
Create your Own Rag to Leverage your Data using papAI solution
To sum up, papAI is a strong platform that makes Retrieval-Augmented Generation (RAG) system development and implementation easier. papAI guarantees that your RAG system is optimized to produce precise, contextually relevant, and high-quality results by facilitating smooth data integration, sophisticated preprocessing, and effective fine-tuning.
It is the perfect option for companies of all sizes wishing to take advantage of AI-powered products because of its scalable design and collaborative capabilities. papAI offers the resources and skills required for success, whether you’re automating information retrieval, increasing decision-making, or optimizing consumer experiences.
Activate Your Free Session with papAI and discover how our innovative platform can drive your success. Click now and take the first step toward building your AI-powered future!
RAG is a natural language processing (NLP) technique that combines a generator, responsible for creating contextually appropriate responses, with a retriever that selects the most relevant information from external data sources.
Fine-tuning optimizes RAG systems by enhancing retrieval accuracy, domain-specific precision, and output coherence. For instance, fine-tuning retrievers ensures that the system selects highly relevant information from external sources, while fine-tuning generators improve the clarity and relevance of the responses. This process helps adapt RAG systems to specific tasks and industries like healthcare, legal, or finance.
- Embedding Models: Transform raw text into dense vector representations for semantic understanding.
- Retrievers: Extract relevant information using sparse (e.g., keyword matching) or dense (e.g., semantic embeddings) retrieval techniques.
- Generators: Convert retrieved data into grammatically coherent, contextually relevant text that is easy to understand.
Fine-tuning enables generators to create more contextually relevant and coherent outputs by training them on task-specific datasets. This process helps the generator align its responses with user intent, domain-specific terminology, and contextual nuances. ensuring high-quality outputs.
- Small to Medium-Sized Enterprises (SMEs): RAG systems automate information retrieval for manageable datasets, improving knowledge management, customer support, and reporting.
- Large Enterprises: RAG systems handle massive datasets in real-time, providing precise, context-aware information and seamless integration with knowledge management systems, which enhances operational efficiency and decision-making.
Interested in discovering papAI?
Our AI expert team is at your disposal for any questions

Why is Deployment Speed the New 2026 AI Moat?
Why is Deployment Speed the New 2026 AI Moat? The...
Read More
We Don’t Just Build AI, We Deliver Measurable Impact
We Don’t Just Build AI, We Deliver Measurable Impact Join...
Read More
AI’s Role in Translating Complex Defence Documentation
AI’s Role in Translating Complex Defence Documentation The defence sector...
Read MoreOptimize RAG Systems Like a Pro with Fine-Tuning
Summary

Article Name
Optimize RAG Systems Like a Pro with Fine-Tuning
DescriptionOptimize RAG systems with fine-tuning to boost performance and Learn proven techniques for smarter, faster AI-driven solutions.
Author
Hocine ousmer
Publisher Name
Datategy
Publisher Logo